
死锁现象
表现一:一个用户A 访问表A(锁住了表A),然后又访问表B,另一个用户B 访问表B(锁住了表B),然后企图访问表A,这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B,才能继续,好了他老人家就只好老老实实在这等了,同样用户B要等用户A释放表A才能继续这就死锁了。
- 解决方法
这种死锁是由于你的程序的BUG产生的,除了调整你的程序的逻辑别无他法
仔细分析你程序的逻辑:
1:尽量避免同时锁定两个资源
2: 必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源. 表现二:用户A读一条纪录,然后修改该条纪录。这时用户B修改该条纪录,这里用户A的事务里锁的性质由共享锁企图上升到独占锁(for update),而用户B里的独占锁由于A有共享锁存在所以必须等A释放掉共享锁,而A由于B的独占锁而无法上升的独占锁也就不可能释放共享锁,于是出现了死锁。
这种死锁比较隐蔽,但其实在稍大点的项目中经常发生。其实这种死锁也可以叫做书签查找所引起的。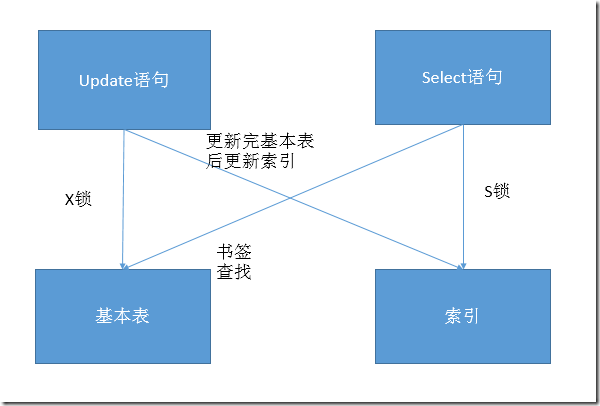 解决方法:
解决方法:
让用户A的事务(即先读后写类型的操作),在select 时就是用Update lock
1 | select * from table1 with(updlock) where .... |
死锁,简而言之,两个或者多个trans,同时请求对方正在请求的某个对象,导致双方互相等待。简单的例子如下:
| trans1 | trans2 |
|---|---|
| 1.IDBConnection.BeginTransaction | 2.IDBConnection.BeginTransaction |
| 2.update table A | 2.update table B |
| 3.update table B | 3.update table A |
| 4.IDBConnection.Commit | 4.IDBConnection.Commit |
好,我们看一个简单的例子,来解释一下,应该如何解决死锁问题。
1 | -- Batch #1 |
上述sql创建一个deadlock的示范数据库,插入了1000条数据,并在表t1上建立了c1列的聚集索引,和c2列的非聚集索引。另外创建了两个sp,分别是从t1中select数据和update数据。
好,打开一个新的查询窗口,我们开始执行下面的query:
1 | -- Batch #2 |
开始执行后,然后我们打开第三个查询窗口,执行下面的query:
1 | -- Batch #3 |
开始执行,哈哈,很快,我们看到了这样的错误信息
Msg 1205, Level 13, State 51, Procedure p1, Line 4
Transaction (Process ID 54) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
pid54发现了死锁。
那么,我们该如何解决它?
在SqlServer 2005中,我们可以这么做:
- 在trans3的窗口中,选择EXEC p1 4,然后right click,看到了菜单了吗?选择Analyse Query in Database Engine Tuning Advisor。
- 注意右面的窗口中,wordload有三个选择:负载文件、表、查询语句,因为我们选择了查询语句的方式,所以就不需要修改这个radio option了。
- 点左上角的Start Analysis按钮
- 出现了一个分析结果窗口,其中,在Index Recommendations中,我们发现了一条信息:大意是,在表t1上增加一个非聚集索引索引:t2+t1。
- 在当前窗口的上方菜单上,选择Action菜单,选择Apply Recommendations,系统会自动创建这个索引。重新运行batch,呵呵,死锁没有了。
为什么会死锁呢?再回顾一下两个sp的写法
1 | CREATE PROC p1 @p1 int AS |
很奇怪吧!p1没有insert,没有delete,没有update,只是一个select,p2才是update。这个和我们前面说过的,trans1里面updata A,update B;trans2里面upate B,update A,根本不贴边啊!
那么,什么导致了死锁?
需要从事件日志中,看sql的死锁信息:
1 | Spid X is running this query (line 2 of proc [p1], inputbuffer “… EXEC p1 4 …”): |
首先,我们看看p1的执行计划。怎么看呢?可以执行set statistics profile on,这句就可以了。下面是p1的执行计划
1 | SELECT c2, c3 FROM t1 WHERE c2 BETWEEN @p1 AND @p1+1 |
我们看到了一个nested loops,第一行,利用索引t1.c2来进行seek,seek出来的那个rowid,在第二行中,用来通过聚集索引来查找整行的数据。这是什么?就是bookmark lookup啊!为什么?因为我们需要的c2、c3不能完全的被索引t1.c1带出来,所以需要书签查找。
好,我们接着看p2的执行计划。
1 | UPDATE t1 SET c2 = c2+1 WHERE c1 = @p1 |
通过聚集索引的seek找到了一行,然后开始更新。这里注意的是,update的时候,它会申请一个针对clustered index的X锁的。
实际上到这里,我们就明白了为什么update会对select产生死锁。update的时候,会申请一个针对clustered index的X锁,这样就阻塞住了(注意,不是死锁!)select里面最后的那个clustered index seek。死锁的另一半在哪里呢?注意我们的select语句,c2存在于索引idx1中,c1是一个聚集索引cidx。问题就在这里!我们在p2中更新了c2这个值,所以sqlserver会自动更新包含c2列的非聚集索引:idx1。而idx1在哪里?就在我们刚才的select语句中。而对这个索引列的更改,意味着索引集合的某个行或者某些行,需要重新排列,而重新排列,需要一个X锁。
SO………,问题就这样被发现了。
总结一下,就是说,某个query使用非聚集索引来select数据,那么它会在非聚集索引上持有一个S锁。当有一些select的列不在该索引上,它需要根据rowid找到对应的聚集索引的那行,然后找到其他数据。而此时,第二个的查询中,update正在聚集索引上忙乎:定位、加锁、修改等。但因为正在修改的某个列,是另外一个非聚集索引的某个列,所以此时,它需要同时更改那个非聚集索引的信息,这就需要在那个非聚集索引上,加第二个X锁。select开始等待update的X锁,update开始等待select的S锁,死锁,就这样发生鸟。
那么,为什么我们增加了一个非聚集索引,死锁就消失鸟?我们看一下,按照上文中自动增加的索引之后的执行计划:
1 | SELECT c2, c3 FROM t1 WHERE c2 BETWEEN @p1 AND @p1+1 |
哦,对于clustered index的需求没有了,因为增加的覆盖索引已经足够把所有的信息都select出来。就这么简单。
实际上,在sqlserver 2005中,如果用profiler来抓eventid:1222,那么会出现一个死锁的图,很直观的说。
下面的方法,有助于将死锁减至最少(详细情况,请看SQLServer联机帮助,搜索:将死锁减至最少即可。
- 按同一顺序访问对象。
- 避免事务中的用户交互。
- 保持事务简短并处于一个批处理中。
- 使用较低的隔离级别。
- 使用基于行版本控制的隔离级别。
- 将 READ_COMMITTED_SNAPSHOT 数据库选项设置为 ON,使得已提交读事务使用行版本控制。
- 使用快照隔离。
- 使用绑定连接
本文链接: https://linbei.top/SQL%E6%AD%BB%E9%94%81%E4%BA%A7%E7%94%9F%E5%8E%9F%E5%9B%A0%E5%92%8C%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!


